# Setting Up a Demo for Maximum Performance
Let's say that your Gradio demo goes _viral_ on social media -- you have lots of users trying it out simultaneously, and you want to provide your users with the best possible experience or, in other words, minimize the amount of time that each user has to wait in the queue to see their prediction.
How can you configure your Gradio demo to handle the most traffic? In this Guide, we dive into some of the parameters of Gradio's `.queue()` method as well as some other related parameters, and discuss how to set these parameters in a way that allows you to serve lots of users simultaneously with minimal latency.
This is an advanced guide, so make sure you know the basics of Gradio already, such as [how to create and launch a Gradio Interface](https://gradio.app/guides/quickstart/). Most of the information in this Guide is relevant whether you are hosting your demo on [Hugging Face Spaces](https://hf.space) or on your own server.
## Overview of Gradio's Queueing System
By default, every Gradio demo includes a built-in queuing system that scales to thousands of requests. When a user of your app submits a request (i.e. submits an input to your function), Gradio adds the request to the queue, and requests are processed in order, generally speaking (this is not exactly true, as discussed below). When the user's request has finished processing, the Gradio server returns the result back to the user using server-side events (SSE). The SSE protocol has several advantages over simply using HTTP POST requests:
(1) They do not time out -- most browsers raise a timeout error if they do not get a response to a POST request after a short period of time (e.g. 1 min). This can be a problem if your inference function takes longer than 1 minute to run or if many people are trying out your demo at the same time, resulting in increased latency.
(2) They allow the server to send multiple updates to the frontend. This means, for example, that the server can send a real-time ETA of how long your prediction will take to complete.
To configure the queue, simply call the `.queue()` method before launching an `Interface`, `TabbedInterface`, `ChatInterface` or any `Blocks`. Here's an example:
```py
import gradio as gr
app = gr.Interface(lambda x:x, "image", "image")
app.queue() # <-- Sets up a queue with default parameters
app.launch()
```
**How Requests are Processed from the Queue**
When a Gradio server is launched, a pool of threads is used to execute requests from the queue. By default, the maximum size of this thread pool is `40` (which is the default inherited from FastAPI, on which the Gradio server is based). However, this does *not* mean that 40 requests are always processed in parallel from the queue.
Instead, Gradio uses a **single-function-single-worker** model by default. This means that each worker thread is only assigned a single function from among all of the functions that could be part of your Gradio app. This ensures that you do not see, for example, out-of-memory errors, due to multiple workers calling a machine learning model at the same time. Suppose you have 3 functions in your Gradio app: A, B, and C. And you see the following sequence of 7 requests come in from users using your app:
```
1 2 3 4 5 6 7
-------------
A B A A C B A
```
Initially, 3 workers will get dispatched to handle requests 1, 2, and 5 (corresponding to functions: A, B, C). As soon as any of these workers finish, they will start processing the next function in the queue of the same function type, e.g. the worker that finished processing request 1 will start processing request 3, and so on.
If you want to change this behavior, there are several parameters that can be used to configure the queue and help reduce latency. Let's go through them one-by-one.
### The `default_concurrency_limit` parameter in `queue()`
The first parameter we will explore is the `default_concurrency_limit` parameter in `queue()`. This controls how many workers can execute the same event. By default, this is set to `1`, but you can set it to a higher integer: `2`, `10`, or even `None` (in the last case, there is no limit besides the total number of available workers).
This is useful, for example, if your Gradio app does not call any resource-intensive functions. If your app only queries external APIs, then you can set the `default_concurrency_limit` much higher. Increasing this parameter can **linearly multiply the capacity of your server to handle requests**.
So why not set this parameter much higher all the time? Keep in mind that since requests are processed in parallel, each request will consume memory to store the data and weights for processing. This means that you might get out-of-memory errors if you increase the `default_concurrency_limit` too high. You may also start to get diminishing returns if the `default_concurrency_limit` is too high because of costs of switching between different worker threads.
**Recommendation**: Increase the `default_concurrency_limit` parameter as high as you can while you continue to see performance gains or until you hit memory limits on your machine. You can [read about Hugging Face Spaces machine specs here](https://huggingface.co/docs/hub/spaces-overview).
### The `concurrency_limit` parameter in events
You can also set the number of requests that can be processed in parallel for each event individually. These take priority over the `default_concurrency_limit` parameter described previously.
To do this, set the `concurrency_limit` parameter of any event listener, e.g. `btn.click(..., concurrency_limit=20)` or in the `Interface` or `ChatInterface` classes: e.g. `gr.Interface(..., concurrency_limit=20)`. By default, this parameter is set to the global `default_concurrency_limit`.
### The `max_threads` parameter in `launch()`
If your demo uses non-async functions, e.g. `def` instead of `async def`, they will be run in a threadpool. This threadpool has a size of 40 meaning that only 40 threads can be created to run your non-async functions. If you are running into this limit, you can increase the threadpool size with `max_threads`. The default value is 40.
Tip: You should use async functions whenever possible to increase the number of concurrent requests your app can handle. Quick functions that are not CPU-bound are good candidates to be written as async. This guide is a good primer on the concept.
### The `max_size` parameter in `queue()`
A more blunt way to reduce the wait times is simply to prevent too many people from joining the queue in the first place. You can set the maximum number of requests that the queue processes using the `max_size` parameter of `queue()`. If a request arrives when the queue is already of the maximum size, it will not be allowed to join the queue and instead, the user will receive an error saying that the queue is full and to try again. By default, `max_size=None`, meaning that there is no limit to the number of users that can join the queue.
Paradoxically, setting a `max_size` can often improve user experience because it prevents users from being dissuaded by very long queue wait times. Users who are more interested and invested in your demo will keep trying to join the queue, and will be able to get their results faster.
**Recommendation**: For a better user experience, set a `max_size` that is reasonable given your expectations of how long users might be willing to wait for a prediction.
### The `max_batch_size` parameter in events
Another way to increase the parallelism of your Gradio demo is to write your function so that it can accept **batches** of inputs. Most deep learning models can process batches of samples more efficiently than processing individual samples.
If you write your function to process a batch of samples, Gradio will automatically batch incoming requests together and pass them into your function as a batch of samples. You need to set `batch` to `True` (by default it is `False`) and set a `max_batch_size` (by default it is `4`) based on the maximum number of samples your function is able to handle. These two parameters can be passed into `gr.Interface()` or to an event in Blocks such as `.click()`.
While setting a batch is conceptually similar to having workers process requests in parallel, it is often _faster_ than setting `default_concurrency_limit` for deep learning models. The downside is that you might need to adapt your function a little bit to accept batches of samples instead of individual samples.
Here's an example of a function that does _not_ accept a batch of inputs -- it processes a single input at a time:
```py
import time
def trim_words(word, length):
return word[:int(length)]
```
Here's the same function rewritten to take in a batch of samples:
```py
import time
def trim_words(words, lengths):
trimmed_words = []
for w, l in zip(words, lengths):
trimmed_words.append(w[:int(l)])
return [trimmed_words]
```
The second function can be used with `batch=True` and an appropriate `max_batch_size` parameter.
**Recommendation**: If possible, write your function to accept batches of samples, and then set `batch` to `True` and the `max_batch_size` as high as possible based on your machine's memory limits.
## Upgrading your Hardware (GPUs, TPUs, etc.)
If you have done everything above, and your demo is still not fast enough, you can upgrade the hardware that your model is running on. Changing the model from running on CPUs to running on GPUs will usually provide a 10x-50x increase in inference time for deep learning models.
It is particularly straightforward to upgrade your Hardware on Hugging Face Spaces. Simply click on the "Settings" tab in your Space and choose the Space Hardware you'd like.
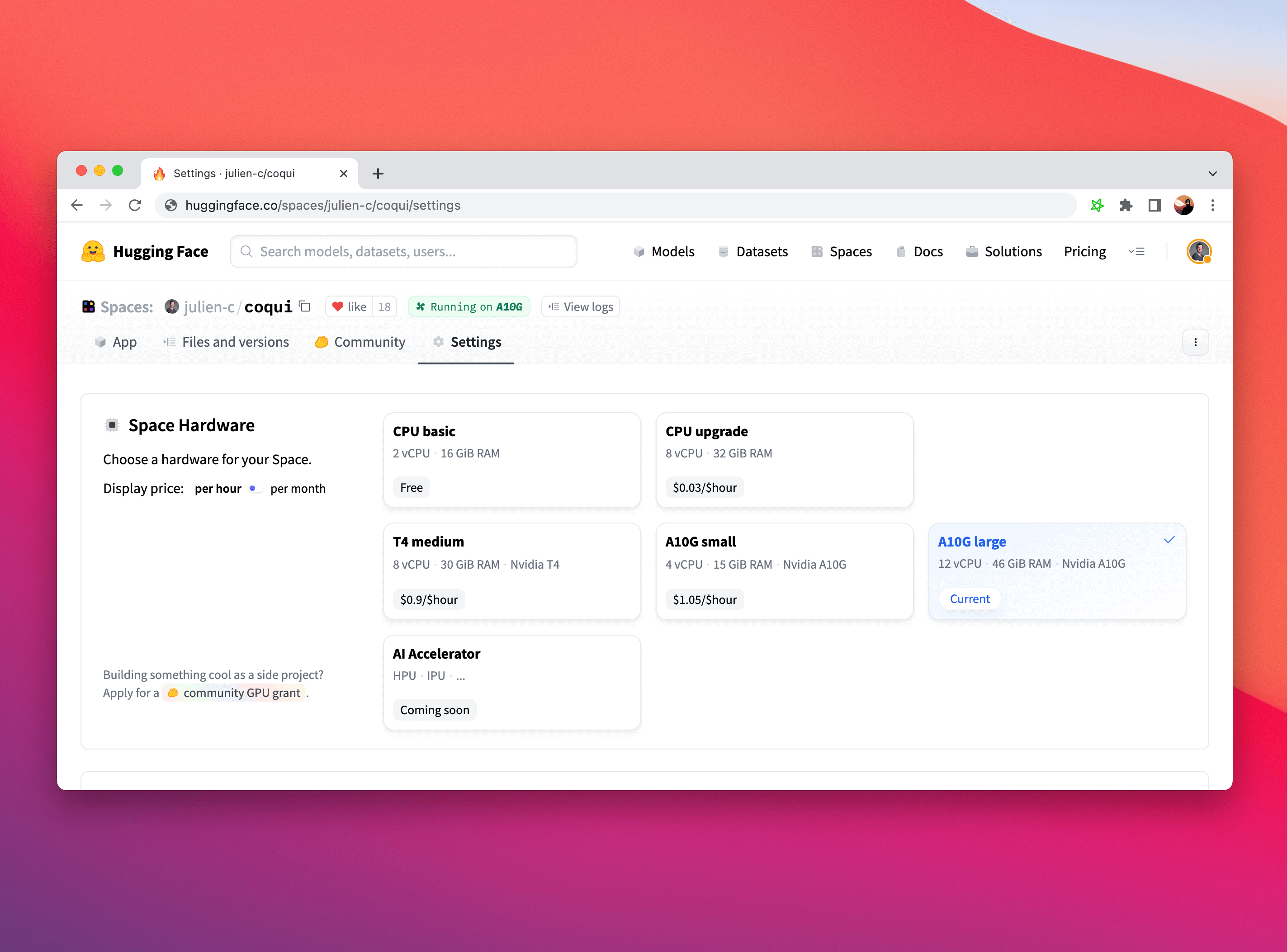
While you might need to adapt portions of your machine learning inference code to run on a GPU (here's a [handy guide](https://cnvrg.io/pytorch-cuda/) if you are using PyTorch), Gradio is completely agnostic to the choice of hardware and will work completely fine if you use it with CPUs, GPUs, TPUs, or any other hardware!
Note: your GPU memory is different than your CPU memory, so if you upgrade your hardware,
you might need to adjust the value of the `default_concurrency_limit` parameter described above.
## Conclusion
Congratulations! You know how to set up a Gradio demo for maximum performance. Good luck on your next viral demo!